
Pandas
업데이트:
개요
pandas는 데이터 분석을 위해 사용되는 패키지 이다. pandas는 크게 세가지의 자료구조를 지원한다.
-
1차원 자료구조
Series
가장 간단한 1차원 자료구조이다. Sequence데이터(배열, 리스트, 딕셔너리)를 입력으로 받아 들인다.
배열의 각 value에 대응되는 index를 부여할 수 있다
import pandas as pd
test = {
'year' : [2019, 2020, 2021],
'price' : [1500, 1600, 1650],
'yield' : [2000, 1500, 1500]}
df = pd.Series(test)
df

-
2차원 자료구조
DataFrame
행과 열이 있는 테이블 데이터를 입력으로 받아들인다. 열은 딕셔너리 형의 key, 행은 value로 취한다.
import pandas as pd
test = {
'year' : [2019, 2020, 2021],
'price' : [1500, 1600, 1650],
'yield' : [2000, 1500, 1500]}
df = pd.DataFrame(test)
df
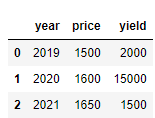
위의 코드와 다른 방식으로 데이터 프레임을 만들어줄 수 있다.
test = [[1500, 2000], #이와 같은 방식은 dict형이 아니라 list형으로 만들어 주어야 한다.
[1600, 1500],
[1650, 1500]]
df = pd.DataFrame(test, index = ['2019년', '2020년','2021년'], columns = ['price', 'yield'])
df
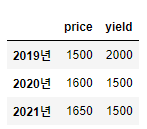
-
3차원 자료구조
Panel은 3개의 축을 가지며 한 축의 요소는 데이터 프레임을 가지고 축 2는 데이터프레임의 행, 축 3은 데이터프레임의 열을 가진다고 한다. 개념이 머리에 잘 들어오지 않지만, 패널은 많이 사용되지 않는다고 한다.
-
index
위 자료구조들을 생성해 줄 때 index 옵션을 부여 해줄 수 있다. index 옵션을 따로 지정해 주지 않는 경우 default 값을 0으로 지정해준다.
-
주요 함수
Series, DataFrame을 만드는 함수는 위에서 다루었으니 다른 쓸만한 함수에 대해서 다루었다.
pd.read_csv(‘csv file’)
아래 코드를 통해서 csv파일을 읽어주면, Dataframe을 얻을 수 있다.
df = pd.read_csv('csv_url')
set_index(‘dataframe col’)
아래와 같이 year를 인덱스로 지정해 줄 경우 해당 열을 index로 사용한다.
test_df = df.set_index(['year'])
df.head(n)
head함수의 n 변수에 정수 값 인자를 넣어 준다면 위에서 n개 만큼 보여준다.
head대신 tail이 들어갈 수 있다.
print(df.head(3))
df.loc[]
df.loc 메서드를 사용하면 행, 열의 데이터를 조회할 수 있다. df.loc의 경우는 다른 메서드들과 다르게
()(소괄호)를 사용하지 않고 [](대괄호)를 사용한다.
먼저 행을 조회하려고 한다면 다음과 같이 작성할 수 있다.
(이곳에서 사용되는 데이터는 두번째 방법으로 생성한 dataframe을 사용했다.)
df.loc['2019년']
위와 같이 작성해주면 Series 타입의 출력을 볼 수 있다.

넣어준 index값을 list로 해준다면 Series가 아닌 DataFrame 출력 한다.
df.loc[['2019년']]

loc안에 들어가는 index 값을 여러개 넣거나, 슬라이딩을 통해서 여러 행을 불러올 수 있다.
df.loc[['2019년', '2020년', '2021년']]
df.loc['2019년':'2021년'] #위 코드와 같은 출력을 보여줄 것이다.
#하지만 대괄호가 한 번만 들어간다.
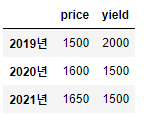
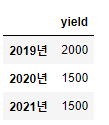
열을 조회하고자 한다면 아래와 같이 앞에 ‘:’을 붙이고 행을 조회했던 방법과 동일하게 사용해주면 된다.
df.loc[:, 'yield']#Series 타입 출력
df.loc[:, ['yield']]#DataFrame 타입 출력
댓글남기기