
토이 프로젝트 리뷰 1
업데이트:
가위바위보 이미지 분류기를 만들어 주기 위해서 먼저 데이터 전처리, 모델 구성, 학습, 테스트 의 순서를 거쳤다.
-
데이터 전처리
데이터 전처리 과정에서는 먼저 데이터를 불러내고, 같은 크기로 수정을 해준 다음 불러낸 데이터 들을 numpy 라이브러리를 통해서 아래와 같이 행렬로 만들어 주었다.
for file in glob.iglob(img_path+'/scissor/*.jpg'):
#가위는 0, 바위는 1, 보는 2로 각 라벨(타겟)을 지정해주었다
img = np.array(Image.open(file),dtype=np.int32)
imgs[idx,:,:,:]=img
labels[idx]=0
idx=idx+1
for file in glob.iglob(img_path+'/rock/*.jpg'):
img = np.array(Image.open(file),dtype=np.int32)
#dtype(data type을 int32로 지정해주며 이를 인자로 넣어주는데, 실수가 아닌 정수로 표현해주겠다는 의미를 갖는다.)
imgs[idx,:,:,:]=img
labels[idx]=1
idx=idx+1
for file in glob.iglob(img_path+'/paper/*.jpg'):
img = np.array(Image.open(file),dtype=np.int32)
imgs[idx,:,:,:]=img
labels[idx]=2
idx=idx+1
위 코드를 함수로 만들어주고, x_train, x_test와 같은 변수에 적절히 할당해 줌으로써 전처리를 마쳤다.
-
모델 구성
다음은 분류기 모델을 구성하는데,
model = keras.models.Sequential
위와 같이 몸통이 될 모델을 할당해주고 이 모델에 레고블럭 과 같이 적절한 layer들을 붙여 줌으로써 모델을 구성할 수 있었다.
가위바위보 이미지 분류기에는 Conv2D , MaxPool2D, MaxPooling2D 와 같은 레이어들로 구성해줬다.
간단하게 Conv2D와 MaxPooling에 관한 Convolution layer와 Pooling layer에 관해서 짚고 넘어가야 할 것 같아서 자그맣게 노트 해보았다.
-
Convolution 레이어(합성곱 레이어)
첫번째 인자는 컨벌루션 필터의 수가 들어가며 두번째 인자는 컨벌루션 커널의(행, 열)이 들어간다.
세번째 인자로는 padding이 들어갈 수 있는데 이는 선택적인 것 같다.
padding은 경계에 대한 처리 방법을 정의하는 곳인데, 아직까지는 깊게 파고들지 않을 것이다. 네번째 인자로는 activation 으로 활성화 함수를 설정하는 곳이다.
이곳에는 linear, relu, sigmoid, softmax가 들어갈 수 있다고 한다. -
Pooling 레이어
더 높은 정확도를 위해서는 필터가 많아야한다.
필터가 늘어나는 것은 곧 차원이 늘어나는 것인데, 차원이 늘어난다면 오버피팅 문제와
이런저런 문제들에 영향을 끼친다고 한다.
이런 문제를 해결하기 위해서 차원을 감소시키는 역할을 하는것이 Pooling Layer라고 한다.
-
Compile
위 Layer들에 관해서는 따로 자세하게 다루는 것이 좋을 것 같다는 생각이 들었다.
이제 여러개의 Layer로 구성을 마친 모델 compile( 모델을 학습시키기 위한 학습 과정을 설정하는 단계 )을 학습시키기 위해 optimizing 해줘야 하는데, 모델을 compile 하는데 필요한 인자들도 잠깐 들여다보면 좋을 것 같다는 생각이 들었다.-
첫번째 인자. optimizer
어떤 사람이 높은 산에서 마을 길을 찾아가는데, 길을 찾아가는 방법은 여러가지가 있을 것이다. 그 때 최적의 길을 찾아가는 방법이 최적화라고 볼 수 있다.
즉, 모델이 input 값을 최대한 빠르고 정확하게 판단하는 방법을 설정해주는 것이 이 optimizer이다.
optimizer에는 정말 많은 종류가 있는데 그중에서도 이를 설명하는 대표적인 ‘짤’을 통해서 대략적인 모습들을 볼 수 있었다.
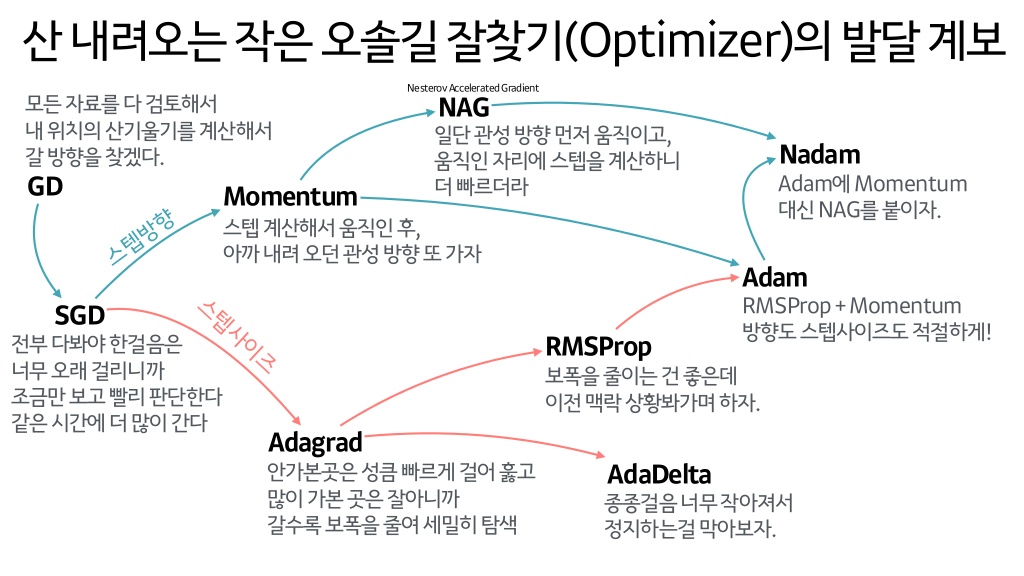 출처 :https://www.slideshare.net/yongho/ss-79607172
출처 :https://www.slideshare.net/yongho/ss-79607172
이 중에서도 adam이 가장 대표적이며 자주 쓰이는 Optimizer로 알려져있다. - 두번째 인자. loss
손실 함수(loss)는 하나의 모델을 컴파일하기 위해 필요한 optimizer와 함께 필요한 매개 변수이다. 이 손실 함수를 통해 얻어낸 loss 값을 통해 실제 정답과 입력된 데이터 사이의 간격을 줄여나가는 것을 목표로 학습된다.
이곳에 들어가는 인자로는 hinge, categorical_hinge, categorical_crossentropy 등이 있다.
이에 관해서는 따로 포스팅이 필요할 것 같다. -
세번째 인자. metrics
metrics는 훈련과정을 모니터링 하는 방식을 설정할 수 있다. 넣을 수 있는 인자로는 아래와 같이 다섯가지(custom 미포함)가 존재한다.- binary_accuracy
- categorical_accuracy
- sparse_categorical_accuracy
- top_k_categorical_accuracy
- sparse_top_k_categorical_accuracy
-
-
학습
모든 전처리와 학습에 필요한 모델 구성을 마치고 학습을 진행했다. 모델 학습을 위한 함수는 아래와 같다.
model.fit(x_train, y_train, epochs = n)여기서 잠깐.
-
epoch?
epoch 는 데이터 셋에 대해서 forward pass 와 backward pass 의 과정을 모두 마친 상태를 말한다.
- forward pass
입력 ~ 출력까지의 각 계층의 가중치를 차례대로 계산하는 과정 - backward pass
출력 ~ 입력층까지의 각 계층의 가중치를 반대로 올라가면서 계산하는 과정
- forward pass
사실 나는 epoch를 쉽게 학습 횟수 정도로 생각했었다 (크나큰 착오일지도 모른다는 생각이 들긴 했지만..)
-
테스트
model.evaluate(x_test, y_test)위 코드를 통해서 테스트를 수행하고 마쳤다.
결과는 0.7정도의 정확도를 기록했다.
-
끝으로..
고등 학생이 수험공부를 하듯, 이전 과정들이 훨씬 복잡하고 어렵게 느껴지고 마지막은 수능과 같이 허무하게 결과가 나왔었다.
첫 토이프로젝트여서 대단한 결과가 나온 것도, 엄청나게 복잡한 과정이 있던 것도 아니었지만, 솔직히는 결과가 나온 것에 감지덕지했다ㅋㅋ..
무지막지한 토이프로젝트들의 난이도 때문에 꾸준한 포스팅은 어렵겠지만 언젠가는 차근차근 뜯어가며 안에서 나오는 개념을 하나하나 정리해 나가려한다. 중요한건 끝까지 끌고 나가는 것이라고 생각한다!
댓글남기기