
seq2seq
업데이트:
개요
시계열은 ‘수열’과 마찬가지로 어떠한 나열이지만 그 척도가 시간이 되는 것을 말한다.
세상에는 이 시계열의 형태인 데이터로 가득차있는데, 언어 데이터 또한 시계열 데이터이다.
시계열 데이터를 처리하는데는 매우 곤란한 문제들이 여럿 있는데, 이를 해결하기 위해 2개의 RNN을 사용하여 어떠한 시계열 데이터를 또 다른 시계열 데이터로 만들어주는 seq2seq(sequence to sequence)모델이 등장했다.
Encoder & Decoder
위에서 seq2seq는 2개의 RNN을 사용한다고 했다.
이 RNN 들은 각각 Encoder와 Decoder라고 불리는데, Encoder는 먼저 입력받은 데이터에서 특징을 토대로 벡터로 변환한다. Encoder에서 나온 출력은 첫 입력에 대한 정보가 응축되어 있다. Decoder는 이 정보를 입력으로 받아 출력을 내게 되고 이 전체적인 프로세스를 seq2seq라고 이해했다.
Encoder
아래는 “나는 고양이로소 이다” 라는 예문을 입력으로 받는 Encoder의 전체 과정이다.
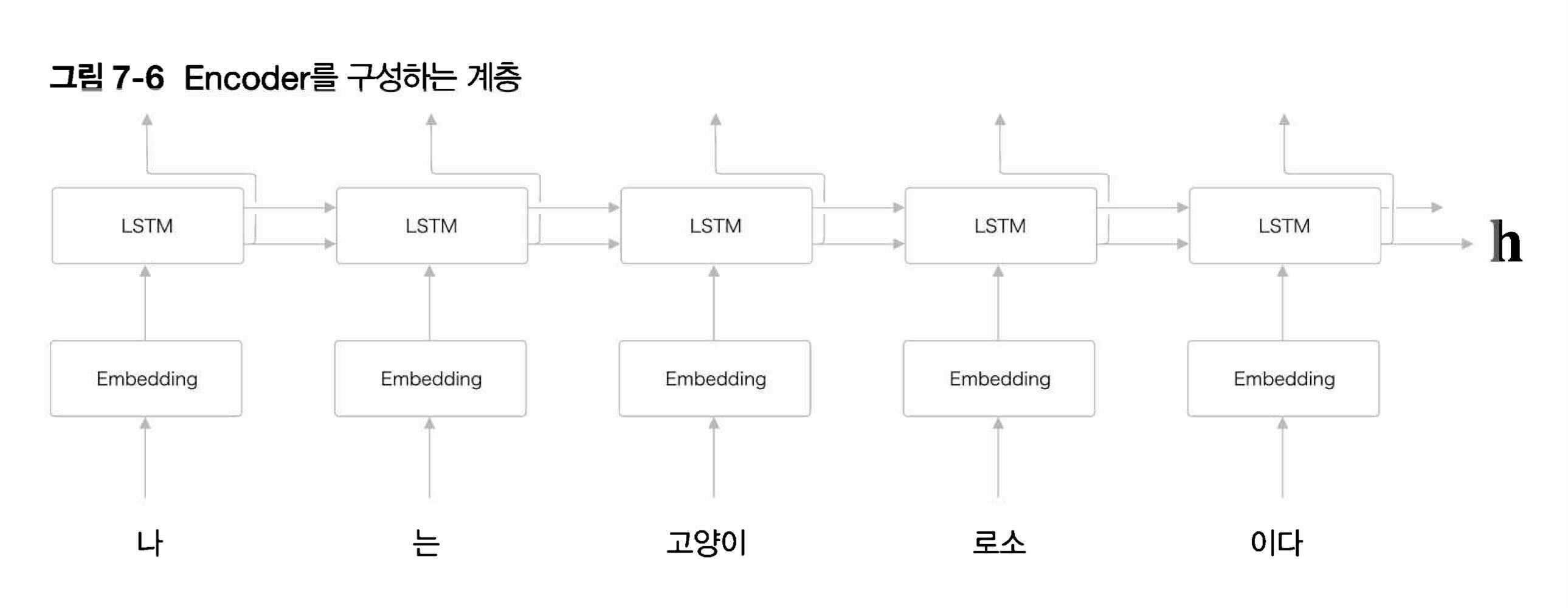
Encoder는 마지막으로 은닉 상태 h를 출력한다. 이 h에 예문을 번역하는데에 필요한 정보가 인코딩 되는데 고정 길이를 가지는 벡터 의 형태를 가지게 된다.
전체적으로 결과만 놓고 보자면, 결국 Encoding이라 함은 정해지지 않은 길이의 문장을 고정 길이를 가지는 벡터로 변환하는 작업이 된다고 할 수 있다.
Decoder
위에서 seq2seq는 Encoder의 출력을 Decoder의 입력으로 사용한다고 언급했다.
거기에 Encoder는 어떤 가변 길이의 정보를 고정 길이의 정보로 바꾼다고 언급했는데, 그렇다면 Decoder는 Encoder로 부터 나온 출력으로 부터 어떻게 결과를 도출해낼까 ?
마찬 가지로 밑시딥2는 아래와 같이 전체적인 과정을 시각화 하여 보여줌으로써 이해를 도왔다.
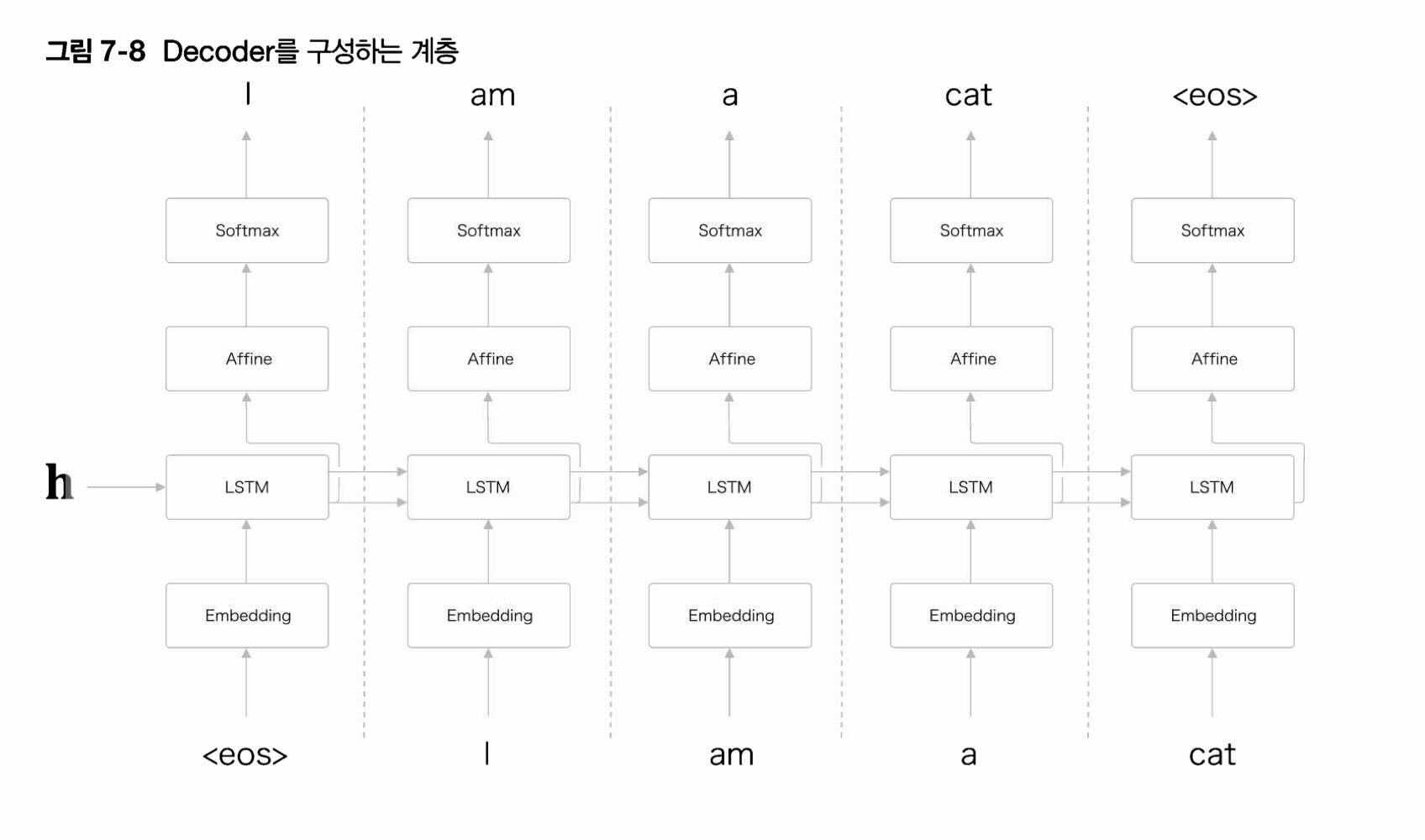
어디서 많이 본듯한 구조라고 생각함과 동시에 아래로 가보니 LSTM을 배웠던 앞절과 완전히 같은 구성 이라고 한다.
하지만 이에 크다면 크고 작다면 작은 차이점이 하나 있는데, LSTM은 원래 h를 입력으로 받지 않았지만 Decoder의 LSTM은 h를 입력받는 차이점 이 있었다.
다른 부가적인 행위없이, h를 입력 받아줌으로써 Decoder는 우리가 원하는 출력을 낸다고 한다.
Encoder + Decoder = seq2seq
seq2seq2가 어떤 구조로 이루어져있고, 그 구조가 어떤 역할을 하는지 살펴보았다.
따라서 마지막으로 아래에 seq2seq의 전체적인 모습과 그 프로세스를 확인할 수 있는 그림을 통해서 seq2seq가 무엇인지 파악할 수 있었다.
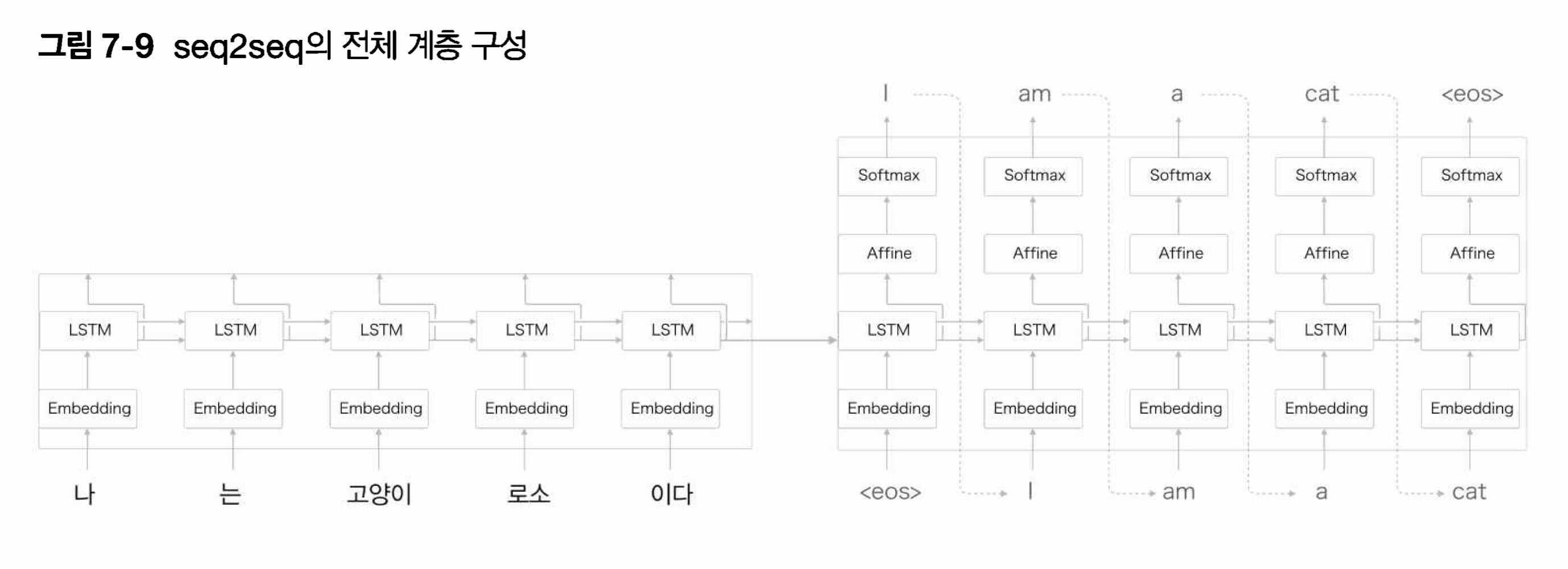
먼저 입력을 받은 Encoder에서 입력받은 문장을 고정 벡터 h로 변환한 후, Decoder에서는 h를 입력으로 받아 도착어를 생성하는 결과를 내는 모습을 확인할 수 있었다.
ref.
[사이토 코키(2019), 밑바닥 부터 시작하는 딥러닝2(한빛 미디어)]
댓글남기기