
Word Embedding
업데이트:
개요
컴퓨터는 단어 그 자체를 받아 들이기 보다는 벡터로 변환된 단어를 처리하는 것이 데이터 처리에 훨씬 탁월하다. 단어를 벡터로 표현하는 방식에는 아래와 같다.
One-hot Encoding
단어 집합(vocabulary)의 크기를 벡터의 차원으로 만들어준다. 이 안에서 표현하고 싶은 단어는 1, 그 외의 단어에는 0을 부여한다. 이렇게 나온 결과를 원-핫 벡터라고 한다.
희소 표현(Sparse Representation)
원-핫 벡터는 원하는 단어를 제외하고는 0의 값을 갖는데, 대부분이 0으로 표현되는 방법을 희소 표현이라고 한다. 따라서 원-핫 벡터는 희소벡터이다.
한계
-
자원적 문제
원-핫 인코딩에서 단어의 개수는 곧 차원이고 단어가 늘어난다면 그만큼 벡터의 차원이 늘어나서 저장해야하는 공간도 늘어난다는 단점이 있다. -
유사도 표현
원-핫 벡터는 단어의 유사도를 표현하지 못한다. 벡터 내에서 표현하려는 단어의 여부를 제외하고는 다른 속성을 나타낼 수 없기 때문.
해결방법
단어의 잠재적 의미(속성)을 다차원 공간에 벡터화하여 표현한다.
이 방법에는 크게 두가지가 있다.
-
카운트 기반
단어의 빈도수를 카운트하며 단어를 수치화 한다.
카운트 기반의 벡터화 방법에는 LSA, HAL 등이 있다. -
예측 기반
다음에 나올 단어에 대한 예측을 기반으로 단어의 뉘앙스를 표현해준다.
NNLM, RNNLM, Word2Vec, Fast Text등이 있다. -
카운트, 예측기반
두 방법을 모두 사용한다!
Glove가 있다.
Word Embedding(워드 임베딩)
-Wikidocs : 딥러닝을 이용한 자연어 처리 입문
Word Embeding은 단어를 벡터로 표현하는 방법이며 단어들을 밀집 표현으로 변환한다.
워드 임베딩은 단어를 벡터로 표현하는 방법 중 하나이다. 이를 표현 하는 방법에는 분산표현, 밀집표현이 있다.
밀집 표현(Dense Representation)
밀집 표편에서는 벡터의 차원을 vocabulary의 크기로 치지 않고 사용자가 임의로 설정한 값으로 벡터 표현의 차원을 맞추게 된다. 또한 벡터는 0과 1로만 표현되는 것이 아니라 실수값을 가지게 되는데 이 실수 값은 훈련 데이터로부터 학습이 된다. 이에 대한 방법으로는 LSA, Word2Vec, FastText, Glove 등이 있다.
분산 표현(Distributed Representation)
분산 표현은 ‘비슷한 위치에서 등장하는 단어들은 비슷한 의미를 가진다’라는 가정으로 부터 나온 방법론으로써 이 방법에 따라 텍스트를 벡터화하면 실제로 의미적으로 가까운 단어가 된다고 한다. 또한 이름대로, 단어의 의미를 여러 차원에 분산하여 표현한다. 이를 통해서 단어 간 유사도를 계산할 수 있다. 이를 위한 학습 방법은 NNLM, RNNLM 등이 있다.
Word2Vec
위에서 참 많은 방법들이 나왔다!
하지만 여러 방법들 중에서도 특히 밀집 표현에 속도도 대폭 개선된 Word2Vec이 많이 쓰이는 것 같다.
먼저 Word2Vec에는 아래와 같이 두 가지 방식이 있다.
CBOW(Continuous Bag of Words)
주변에 있는 단어들을 가지고 중간에 있는 단어들을 예측한다. 아래 이미지를 통해서 쉽게 이해할 수 있었다.
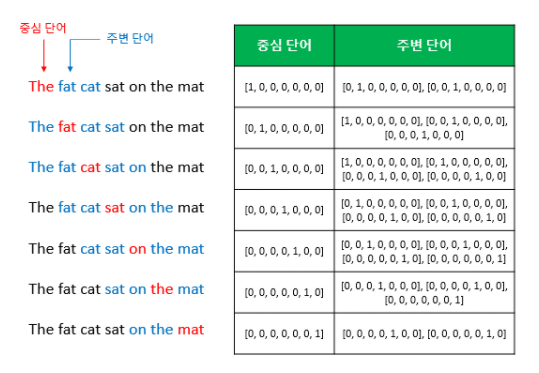
위의 이미지를 통해 보자면, CBOW가 하는 일은 중심 단어를 예측하기 위해서 임의로 정해준 예측 단어의 범위인 Window를 계속 움직이면서 예측을 한다는 내용의 아주 간략하게 표현한 것이다.
방식은 이것으로 충분히 이해가 됐고, 인공신경망에 대한 도식화는 다음과 같다.
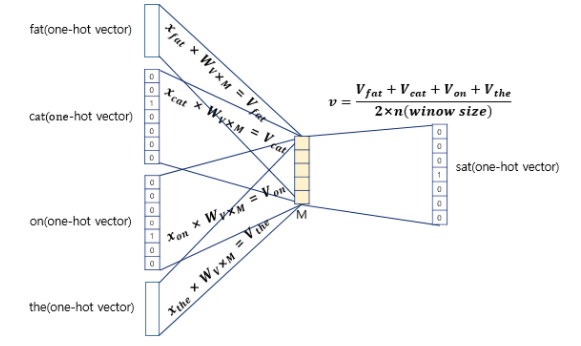
입력은 원-핫 벡터로 이 벡터에 대해서 W를 곱해서 생겨진 벡터들이 중간에 투사층을 지나 벡터들의 평균을 구한 벡터를 만들게 된다.
이 평균 벡터는 두번째 가중치 행렬과 곱해져 다른 원-핫 벡터들과 차원이 동일한 벡터가 나오게 되는데 이에 소프트맥스를 취하면 원소들이 0과 1사이의 값을 갖게 된다. 그리고 이 벡터에 손실 함수 cross-entropy를 사용하면 이미지와 같이 단어가 예측되는 것을 확인 할 수 있다.
<img alt = “CBOW3.png”src = “../../assets/images/Embedding/CBOW3.png”>
Skip-Gram
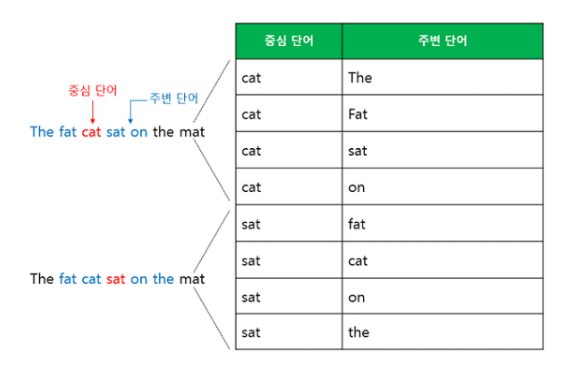
중간에 있는 단어로 주변 단어들을 예측한다.
Skip-Gram의 인공신경망을 도식화하면
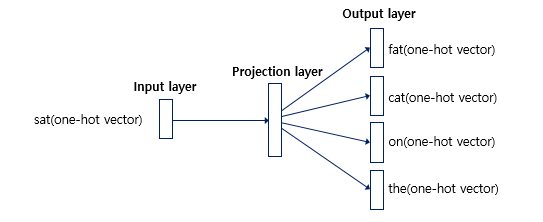
이와 같은데 위에서의 CBOW와 다르게 훨씬 단순하다.
투사층에서 벡터들의 평균을 구하는 과정이 없기 때문이다. Simple is the best라는 말이 새삼 떠오르듯, Skip-gram이 전반적으로 CBOW보다 성능이 좋다고 한다.
댓글남기기