
[JPA] JDBC에서 JPA 까지
업데이트:
JDBC
JDBC는 자바에서 데이터베이스에 접속할 수 있도록 도와주는 자바 API로써 자바 애플리케이션에 사용하는 DBMS에 종속되지 않고 DB를 처리한다. 마치 전압을 알아서 변경해주는 어댑터와도 같다.
JDBC에서는 쿼리를 날리기까지 아래 예시와 같은 과정을 거친다.
static final String JDBC_DRIVER = "org.h2.Driver";
static final String DB_URL = "jdbc:h2:~/test";
static final String USER = "sa";
static final String PASS = "";
static final String DROP_TABLE_SQL = "DROP TABLE customers IF EXISTS";
static final String CREATE_TABLE_SQL = "CREATE TABLE customers(id SERIAL, first_name VARCHAR(255), last_name VARCHAR(255))";
static final String INSERT_SQL = "INSERT INTO customers (id, first_name, last_name) VALUES(1, 'yeoooo', 'dev')";
public void jdbc_sample() throws Exception {
try {
Class.forName(JDBC_DRIVER);
Connection connection = DriverManager.getConnection(DB_URL, USER, PASS);
log.info("GET CONNECTION");
PreparedStatement ps = connection.prepareStatement(DROP_TABLE_SQL);
ps.executeUpdate();
ps = connection.prepareStatement(CREATE_TABLE_SQL);
ps.executeUpdate();
log.info("CREATE TABLE");
ps = connection.prepareStatement(INSERT_SQL);
ps.executeUpdate();
ResultSet rs = connection.createStatement().executeQuery("SELECT * FROM customers WHERE id = 1");
while (rs.next()) {
log.info(rs.getString("first_name") + " " + rs.getString("last_name"));
}
ps.close();
connection.close();
} catch (Exception e) {
e.printStackTrace();
}
}
- Class.forName을 통해 드라이버를 로드한다.
- DriverManger로부터 Connection을 얻어낸다.
- connection을 통해 statement나 preparedstatement(날릴 질의)를 만든다.
- excuteUpdate를 통해 질의를 날린다.
※ Class.forName()
여기서 1. 의 Class.forName은 인스턴스를 받는 참조변수나 대입이 존재하지 않는다 . 하지만 드라이버 내의 static 블럭이 어떤 생성자보다 먼저 실행되는 코드 이기 때문에 JDBC 드라이버와 같이 인스턴스를 별도로 관리하지 않는 대부분의 클래스의 경우 정적 블록을 통해 생성하고 관리한다.
따라서 forName()을 호출하면 인스턴스 생성과 초기화가 이루어진다. 이는 JDBC4.0 이후로 메소드를 호출하지 않아도 자동으로 드라이버를 초기화하게 되었다.
출처 : https://kyun2.tistory.com/23
JDBC를 사용하다보면 자연스레 쿼리의 양이 많아지고 그만큼 처리해야할 예외들의 수도 많아진다.
이를 해결하고 단순화 하기 위해 Template이 등장했다.
JDBC Template
public class JDBCTemplateTest {
static final String JDBC_DRIVER = "org.h2.Driver";
static final String DB_URL = "jdbc:h2:~/test";
static final String USER = "sa";
static final String PASS = "";
static final String DROP_TABLE_SQL = "DROP TABLE customers IF EXISTS";
static final String CREATE_TABLE_SQL = "CREATE TABLE customers(id SERIAL, first_name VARCHAR(255), last_name VARCHAR(255))";
static final String INSERT_SQL = "INSERT INTO customers (id, first_name, last_name) VALUES(1, 'yeoooo', 'dev')";
@Autowired
JdbcTemplate jdbcTemplate;
@Test
public void jdbcTemplateTest() throws Exception {
jdbcTemplate.update(DROP_TABLE_SQL);
jdbcTemplate.update(CREATE_TABLE_SQL);
String name = jdbcTemplate.queryForObject(
"SELECT * FROM customers WHERE id = 1",
(resultSet,i) -> resultSet.getString("first_name) + " " + resultSet,getString("last_name"));
}
}
JDBC에서 데이터 계층에 접근하기 위해 Connection, steatement 객체를 만들고 닫아주는 과정을 생략할 수 있게 되었다.
JDBC Template은 아래 일련의 과정을 거쳤다.
- JDBC Template을 초기화
- jdbcTemplate.update()를 통해 쿼리 실행
하지만 이러한 방식은 쿼리와 코드가 섞이게 되어 유지보수가 어려워지게 되었다.
이점을 해결하기 위해 QueryMapper인 Mybatis가 등장했다.
MyBatis
Mybatis는 반복적인 JDBC 프로그래밍을 단순화하고 SQL 쿼리들을 코드와 분리할 수 있다. 또한 Mybatis를 통해 동적쿼리를 만들어낼 수 있다.
myBatis를 AutoConfiguration을 통해 빈으로 등록하기 위해서는 Application.yml 또는 Application.properties에 다음과 같이 설정해주어야한다.
mybatis:
type-aliases-package: com.kdt.lecture.repository.domain
configuration:
map-underscore-to-camel-case: true
default-fetch-size: 100
default-statement-timeout: 30
mapper-locations: classpath:mapper/*.xml
type-aliases-package: java Result Set을 사용하기에 번거로움이 있었던 JDBC, JDBCTemplate. 자바 객체에 ResultSet을 자동으로 매핑해준다. type-aliases-package는 어떤 객체에 매핑해줄 것인지 정해줄 수 있다.map-underscore-to-camel-case: DB의 언더바(_)로 명시되어있는 컬럼을 Camel Case로 변환해 매핑한다.default-fetch-size: SELECT ALL QUERY를 한 번에 몇개 씩 가져올건지 정할 수 있다.default-statement-timeout: statement의 기본적인 timeout시간을 정해줄 수 있다.mapper-locations: 쿼리를 어디에서 관리할 것인지 명시해줄 수 있다.
쿼리를 관리할 xml파일에서는 다음과 같은 설정으로 작성할 수 있다.
- mapper의 위치를 namspace에 명시한다
- 사용할 쿼리와 그 메서드 이름을 명시한다
- 쿼리 내용을 작성한다
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.kdt.lecture.repository.CustomerMapper">
<insert id="save">
INSERT INTO customers(id, first_name, last_name)
VALUES (#{id}, #{firstName}, #{lastName})
</insert>
<select id="findById" resultType="customers">
SELECT *
FROM customers
WHERE id = #{id}
</select>
</mapper>
이 다음으로 xml mapper를 읽고 처리할 Mapper 인터페이스를 만들어준다.
package com.kdt.lecture.repository;
import com.kdt.lecture.repository.domain.Customer;
import org.apache.ibatis.annotations.Mapper;
@Mapper
public interface CustomerMapper {
void save(Customer customer);
Customer findById(long id);
}
- @Mapper를 명시한다.
- 작성한 xml의 쿼리 id와 맞추어 메서드를 명시한다.
만들어진 Mapper를 아래와 같이 사용할 수 있다.
@Slf4j
@SpringBootTest
public class MybatisTest {
static final String DROP_TABLE_SQL = "DROP TABLE customers IF EXISTS";
static final String CREATE_TABLE_SQL = "CREATE TABLE customers(id SERIAL, first_name VARCHAR(255), last_name VARCHAR(255))";
@Autowired
JdbcTemplate jdbcTemplate;
@Autowired
CustomerMapper customerMapper;
@Test
public void saveTest() throws Exception {
jdbcTemplate.update(DROP_TABLE_SQL);
jdbcTemplate.update(CREATE_TABLE_SQL);
customerMapper.save(new Customer(1L, "yeoooo", "dev"));
Customer customer = customerMapper.findById(1L);
log.info("fullName : {} {}", customer.getFirstName(), customer.getLastName());
}
}
- Mapper를 @Autowired를 통해 초기화한다.
- Mapper에 등록된 메서드를 사용한다.
이렇게 Mapper를 이용하게 되면서 RDB와의 통신이 더욱 편리하게 되었지만
RDB와 자바객체가 가지는 패러다임의 불일치가 생기게된다.
이는 객체와 RDB를 매핑해주는 Object Relational Mapping(ORM), JPA를 통해 극복할 수 있다.
JPA(ORM Mapper)
JPA는 자바 진영의 ORM에 대한 API 표준 명세로써 객체의 참조로 연관관계를 저장할 수 있다. Mybatis의 경우, 직접 쿼리를 작성해서 이를 POJO객체에 매핑해 쿼리 결과를 객체로 변환해 가져올 수 있었다.
JPA을 빈으로 등록해 사용하기 위해서 Application.yml에 다음과 같은 기본 설정 값을 줄 수 있다.
spring:
datasource:
driver-class-name: org.h2.Driver
url: jdbc:h2:~/test
username: sa
password:
jpa:
generate-ddl: true
open-in-view: false
show-sql: true
generate-ddl: DDL 생성 시 데이터베이스 고유의 기능을 사용할지에 대한 설정open-in-view:show-sql: jpa나 hibernae를 통해 CRUD를 실행하면 해당 CRUD의 sql을 로그로 보여준다.- 더욱 많은 properties에 대해서는 이곳에서 확인할 수 있다.
아래에 JPA를 사용해 Entity를 만들어준다.
@Entity
@Table(name = "customers")
@Getter
@Setter
public class CustomerEntity {
@Id
private Long id;
private String firstName;
private String lastName;
...
}
@Entity를 통해 해당 클래스가 엔티티임을 명시한다.@Table을 통해 DB에 들어갈 테이블 명을 명시할 수 있다.@Id를 통해 Primary Key를 명시할 수 있다. 키가 될 속성에는@GeneratedValue를 통해 값을 생성할 수 있다.
Entity를 설정하고 이를 저장할 Repository를 작성해준다.
public interface CustomerRepository extends JpaRepository<CustomerEntity, Long> {//2022-08-8_yeoooo : <객체, 아이디>
}
- JpaRepository를 implement 한다. 이때 Generics에 들어갈 값은 저장할 객체와 그 Primary Key의 타입이다.
만들어진 저장소를 토대로 CRUD를 구현해 보았다.
@SpringBootTest
@Slf4j
class JPACRUDTest {
@Autowired
CustomerRepository repository;
@BeforeEach
void setUp() {
}
@AfterEach
public void tearDonw() throws Exception {
repository.deleteAll();
}
@Test
public void Insert_test() throws Exception {
//given
CustomerEntity customer = new CustomerEntity();
customer.setId(1L);
customer.setFirstName("Yeoooo");
customer.setLastName("dev");
//when
repository.save(customer);
//then
CustomerEntity entity = repository.findById(1L).get();
log.info("{} {}", entity.getFirstName() + " " + entity.getLastName());
}
@Test
@Transactional
public void updateTest() throws Exception {
//given
CustomerEntity customer = new CustomerEntity();
customer.setId(1L);
customer.setFirstName("Yeoooo");
customer.setLastName("dev");
repository.save(customer);
//when
CustomerEntity entity = repository.findById(1L).get();
//then
entity.setFirstName("hama");
entity.setLastName("dev");
CustomerEntity updated = repository.findById(1L).get();
log.info("{} {}", updated.getFirstName(), updated.getLastName());
}
}
JPA에서의 CRUD 구현은 간편하다.
앞서 작성해둔 JpaRepository를 implement 함으로써 구현체인 CustomerRepository에 CRUD를 위한 기본적인 메서드들이 구현되어 있기 때문에, 이를 사용해주기만 하면 된다.
- CustomerRepository를 초기화한다.
- 구현체의 메서드를 사용한다.
- Transaction을 사용하기 위해(Persistence Context가 관리하게 할 )메서드에 @Transactional을 명시한다.
@Transactional
Spring에서는 @Transactional로 트랜잭션 처리를 지원한다.
@Transactional이 추가되면 해당 메서드나 클래스에 트랜잭션 기능이 적용된 Proxy 객체가 생성된다.
@Transactional을 명시한 메서드 또는 클래스는 내부적으로 생성된 Proxy 객체를 이용한 AOP를 통해 트랜잭션 처리코드가 실행 전 후로 수행된다.
프록시를 이용한 @Transactional 작동 원리의 구상도는 아래와 같다.
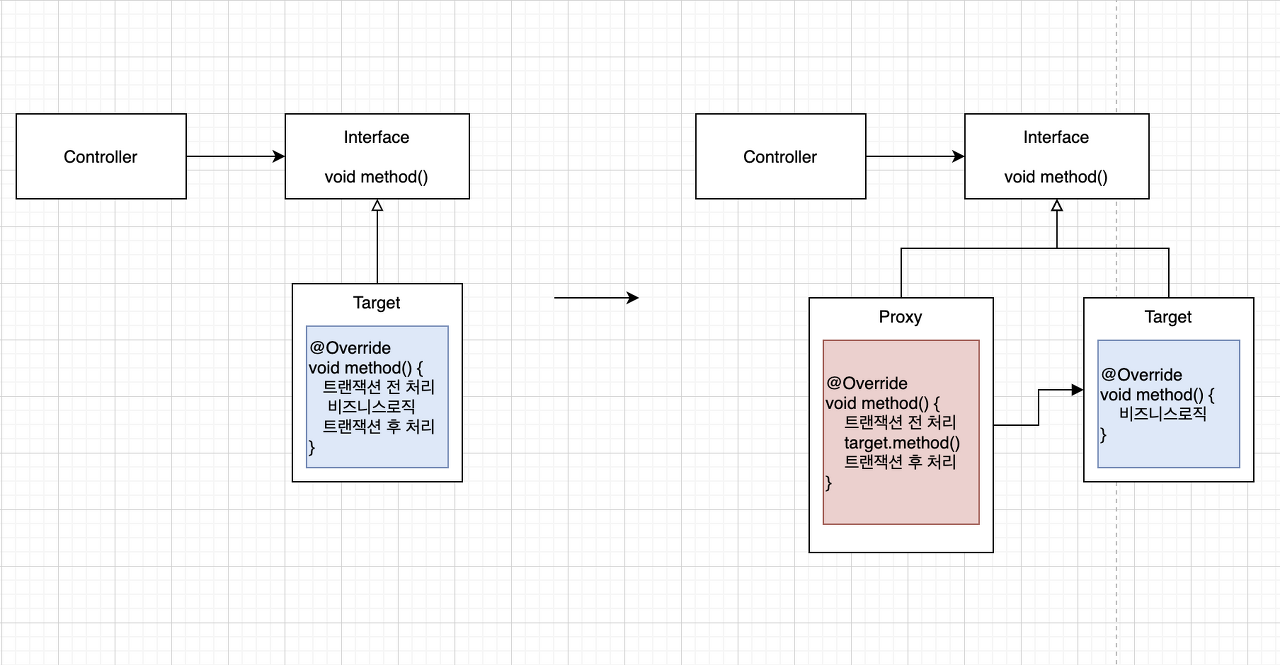
출처:[https://hwannny.tistory.com/98](https://hwannny.tistory.com/98)
이와 같이 Transaction을 마치고 나면 그 결과(오류, 성공)에 따라 Commit 또는 Rollback을 하게된다.
여담으로, Test 안에서의 Transaction은 자동으로 Rollback이 되는데, 이를 원치 않는 경우 테스트 메서드에 @Rollback(value = false)를 명시해줌으로써 롤백을 막을 수 있다. 기본값은 true이다.
@Transactional 속성
격리수준, @Transactional(isolation = Isolation.?)
일관성 없는 데이터에 대한 허용수준을 설정할 수 있다.
-
DEFAULT기본 격리 수준
-
READ_UNCOMMiTTED(level 0)커밋되지 않은 데이터에 대한 읽기를 허용. Dirty Read가 발생한다.
-
READ_COMMITTED(level 1)커밋된 데이터에 대한 읽기만을 허용. Dirty Read를 방지한다.
-
REPEATABLE_READ(level 2)트랜잭션이 완료될 때까지 SELECT 문장을 사용하는 모든 데이터에 shared lock이 발생해 다른 사용자의 그 영역에 관한 데이터에 대한 수정을 막는다. Non-Repeatable Read를 방지한다.
-
SERIALIZABLE(level 3)데이터의 일관성 및 동시성을 위해 MVCC를 사용하지 않는다.
(MVCC, Mulit Version Concurrency Control이란 데이터를 조회할 때 LOCK을 사용하지 않은 상태로 데이터의 버전을 관리해 데이터의 일관성과 동시성을 높이는 기술이다.)
REPEATABLE_READ와 같으나 입력 또한 불가능하다.
Phantom Read를 방지한다.
전파, @Transactional(propagation = Propagation.?)
트랜잭션 동작 중 다른 트랜잭션을 실행하는 상황에서의 동작을 설정할 수 있다.
-
REQUIRED(DEFAULT)부모 트랜잭션 내에서 실행한다. 부모 트랜잭션이 없다면, 새로운 트랜잭션을 생성한다.
-
SUPPORTS이미 시작된 트랜잭션이 존재하는 경우에 그 트랜잭션에 참여하고 그렇지 않은 경우 트랜잭션 없이 진행한다.
-
REQUIRES_NEW부모 트랜잭션과 관계없이 무조건 새로운 트랜잭션을 생성한다.
호출된 부분에서 이미 작동중인 트랜잭션이 존재한다면 기존 트랜잭션의 메소드가 종료될 때 까지 대기 상태로 두고 자신의 트랜잭션을 실행한다.
-
MANDATORY이미 시작된 트랜잭션이 있는 경우 참여한다.
트랜잭션이 없는 경우 예외를 발생시킨다.
독립적으로 실행되면 안되는 트랜잭션인 경우 사용할 수 있다.
-
NEVER트랜잭션을 사용하지 않도록 강제한다.
이미 작동중인 트랜잭션이 존재한다면 예외를 발생시킨다.
-
NESTED이미 작동중인 트랜잭션이 있는 경우 중첩으로 트랜잭션을 실행한다.
부모 트랜잭션이 존재하는 경우 부모 트랜잭션에 중첩시키고, 그렇지 않은 경우 새로운 트랜잭션을 생성한다.
부모 트랜잭션에 예외가 발생한다면 자식 트랜잭션 또한 Rollback된다.
반대로 자식 트랜잭션에 예외가 발생한다면 부모 트랜잭션은 Rollback 되지 않는다.
읽기 전용 트랜잭션, @Transactional(readOnly = ?)
성능 최적화에 사용되며 트랜잭션에 쓰기 작업 허용하지 않기위해 사용한다. 쓰기 작업과 관련된 질의가 동작되면 예외가 발생한다.
true
트랜잭션을 읽기 전용으로 사용한다.
false(DEFAULT)
트랜잭션에게 쓰기 작업을 허용한다.
롤백 예외 , @Transactional(rollbackFor = ?\ norollbackFor =?)
-
rollbackFor값으로 들어간 예외 클래스의 예외가 발생한다면 강제로 rolback한다.
-
noRollbackFor값으로 들어간 예외 클래스의 예외가 발생한다면 rollback하지 않는다.
타임 아웃, @Transactional(timout = ?)
- 지정한 시간 내에 해당 메소드 수행이 완료되지 않는다면 rollback 한다.
- 단위는
초이다. -1인 경우 시간 한계가 존재하지 않는다.
JPA의 영속성 컨텍스트를 이용하면 update query를 이용하지 않아도 조회한 Entity 객체를 수정하면 변경을 감지 하고 POJO와 RDB 의 테이블을 매핑해 객체가 변경되면 테이블도 같이 변경되어 RDB의 테이블을 마치 자바의 객체처럼 다룰 수 있게 도와준다.
JPA의 이점
-
생산성을 증진 시킨다.
SQL에 의존적인 개발에서 탈피, 객체 중심으로 개발이 가능하다.(데이터에 수정, 속성의 추가가 일어날 경우 SQL을 일일이 수정하지 않아도 된다.)
-
객체와 관계형 테이블의 패러다임 불일치를 방지한다.
객체 지향의 이점을 누리게 된다. (추상화, 캡슐화, 다형성, 상속)
댓글남기기