
Data preprocessing(데이터 전처리)_결측치
업데이트:
개요
딥러닝을 하기 위해서 데이터 전처리는 꼭 필요한 작업이다.
전처리가 이루어지지 않았을 때 모델이 학습을 수행하는데에 많은 에러를 발생시킬 수 있고, 모델에서 데이터를 통해 학습을 수행할 때 성능에서의 차이또한 보여주기 때문이다.
이러한 이유 때문에 "데이터 분석의 8할은 전처리 이다" 라고 한다.
이렇게 성능 차이까지 야기하는 전처리를 하는 이유는 다음과 같다.
전처리가 충분히 되지 않은 데이터를 사용할 경우 분석 결과의 신뢰도가 떨어지게 되어 예측 모델의 정확도도 떨어진다.
이러한 전처리에는 여러가지 기법이 있는데 그 기법에 대해 하나씩 들여다 보려고 한다.
- 준비
데이터를 전처리하기 위해 먼저 모듈을 불러오고 데이터를 준비해 준다.
import pandas as pd
import os
import matplotlib.pyplot as plt
csv_path = os.getenv('HOME')+'/datas/contact.csv'
contact = pd.read_csv(csv_path)
- 결측치 제거
- 중복 데이터 제거
- 이상치 제거
- 정규화
- One-Hot Encoding
- Binning(구간화)
결측치 제거
결측치란 ?
결측치는 NULL DATA를 뜻한다. 분석하려는 데이터에 결측치가 포함되어 있다면 함수 사용에 문제가 발생하고 분석 결과에 왜곡이 생기게 된다.
제거 방법
- 결측치 데이터 제거
먼저 결측치 여부를 확인해 준다.print('datas : ' len(contact)) datas : 199전체 데이터 - 값이 있는 데이터 = 결측치 수
이기 때문에 이를 코드로 옮겨준다.len(contact)-contact.count() #결과는 컬럼별로 나온다. 기간 0 국가명 0 수출건수 0 수입건수 3 수입금액 3 무역수지 4 기타사항 199전체 데이터 199개 중에서 기타사항은 199개 모두 결측치이다. 이런 경우에는 정보가 없는 컬럼이기 때문에 삭제해준다.
contact = contact.drop('기타사항', axis = 1)이런 경우는 간단하지만, 위의 수출건수, 수입건수 등에서는 전체가 아니라 일부에서만 결측치를 확인할 수 있었다.
따라서 부분적으로 삭제 또는 대체 해주어야 한다.Pandas의 Dataframe에서는 열이나 행을 조작, 조회할 수 있는 메서드를 가지고 있는데 이곳에서는 null값인지를 확인 해주고 여부에 따라 True(결측치가 존재하는 경우), False로 반환해주는 DataFrame.isnull()과 행마다 하나의 True라도 존재한다면 True, 반대의 경우 False를 반환하는 Dataframe.any(axis=1)을 사용한다.
contact.isnull()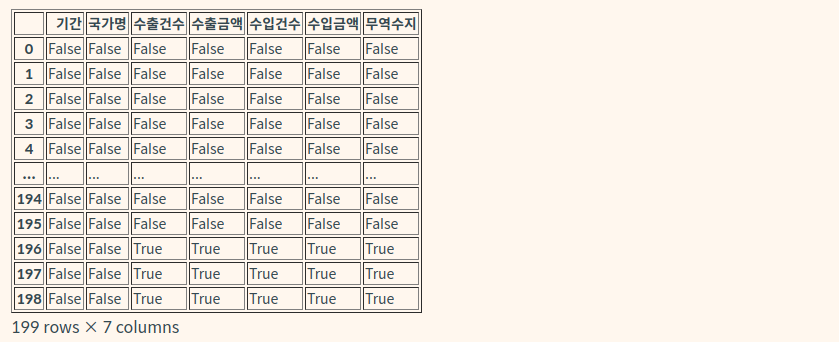
contact = isnull().any(axis = 1) # 0 False # 1 False # 2 False # 3 False # 4 False # ... # 191 True # 192 False # 193 False # 194 False # 195 False # Length : 195, dtype : bool #위의 데이터는 Series 타입.196, 197, 198데이터의 경우 기간과 국가명을 제외하고 모두 결측치이다. 신뢰성이 떨어지는 데이터라고 판단되기 때문에 이 데이터들은 삭제되어야 한다.
- 결측치 데이터 대체
trade[trade.isnull().any(axis=1)]
하지만 191 데이터의 경우 수출금액과 무역수지 두 컬럼에서만 결측치를 갖기 때문에 삭제하기보다는 어떠한 값으로 대체해주는 것이 좋다.
대체 방법
대체 하는 방법에는 아래가 있다.
- 특정 값 삽입
- 평균, 중앙값 삽입
- 다른 데이터를 통한 예측 값
- 시계열 데이터 특성을 이용한 예측 값
이번에는 평균 값을 사용해 값을 채워보았다.
trade.loc[191, '수출금액'] =(contact.loc[188, '수출금액']+contact.loc[104, '수출금액'])/2
trade.loc[[191]]

데이터 전처리는 필수적이고, 다양한 방법이 존재하며 그에 따라 효율도 다르다.
다음 포스팅에서는 중복 데이터 삭제에 관해서 다룰 것이다.
댓글남기기